本文共 4233 字,大约阅读时间需要 14 分钟。
也许你对降级已经有了一些认识,认真看完,我想这篇文章可能会给你带来一些新的收获~
前面两篇我们已经聊过了「熔断」()和「限流」(),这次我们聊的就是「高可用三剑客」中剩下的「降级」。
不知道这里有多少小伙伴接触过阿里的开放平台。在每次大促的时候,阿里都会发布这样的一个公告。
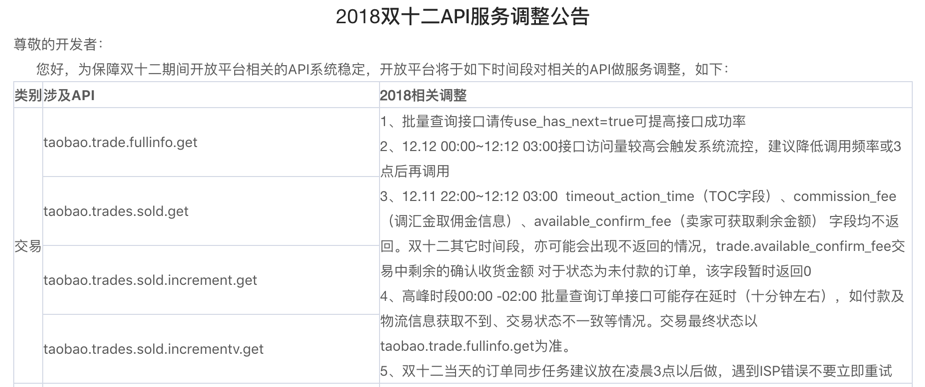
这些调整就是「降级」工作,目的是为了腾出更多资源给核心程序使用,以最大化保证核心业务的可用性,因此就必然需要对非核心业务执行一些降级处理。
一、什么是「降级」
降级的目的用一句话概括就是:将有限的资源效益最大化。
什么样才是效益最大化呢?就像下面这个例子:
z哥有3个东西要买,一个3000的A、一个700的B、一个1200的C,对z哥的重要程度A\u0026gt;B\u0026gt;C。但此时,z哥手里只有3000块钱,你说z哥该怎么选才能把钱花的最多?必然是选A咯。根据28原则,我们知道一个系统80%的效益是由最核心的20%的功能产出的。剩下的20%效益需要投入80%的资源才能达到。
这就意味着,假如系统平时需要花费100%资源做100%的事情,如果现在访问量增多3倍的话必定扛不住(需要300%的资源)。那么,在不增加资源的情况下,我希望系统不能宕机,依旧能正常工作,必然需要让出那解决剩下20%问题的80%资源。如此一来,理论上这100%的资源就可以支撑原先5倍的访问量。副作用是功能的完整性上受损80%。
当然,在实际的场景中不会降级掉80%的功能这么夸张,毕竟还得为用户的体验考虑。
举个电商场景典型的例子,在大促的时候,最重要的是什么?转化咯~赚钱咯~ 那么这个时候如果说「评论」功能占用了很多资源,你会怎么处理?其实我们可以选择临时关闭提交评论入口、关闭翻页功能等等,让下单的过程有更多的资源来处理。
常见的降级方案表现形式无非以下三种类型。
1.牺牲用户体验
为了减少对「冷数据」的获取,禁用列表的翻页功能。
为了放缓流量进入的速率,增加验证码机制。
为了减少“大查询”浪费过多的资源,提高筛选条件要求(禁用模糊查询、部分条件必选等)。
用通用的静态化数据代替「千人千面」的动态数据。
甚至更简单粗暴的,直接挂一个页面显示「XX功能在XX时间内暂时关闭」。
此类方案虽然或多或少降低了用户的体验,但是在某些时期,有些功能并不是「刚需」。以此换取对系统的保护是笔划算的买卖。
2.牺牲功能完整性
还有一些功能是「防御性」的,如果愿意冒险“裸奔”一段时间也会带来可观的资源节约。
比如通过临时关闭「风控」、取消部分「条件是否满足」的判断(如,将积分商品添加到购物车时判断积分够不够)等操作,减少这类「验证」动作以释放更多的资源。
又或者将原本info、warning级别的日志采集关闭或者直接不采集,仅采集error以及fault级别的日志。
3.牺牲时效性
一个事件发生后立马看到效果是一个很符合「思维惯性」的东西。但是根据之前的一篇文章()我们知道,时效性这个东西一旦涉及到网络传输是不存在真正的“实时”的。但是为了尽可能快的将处理后的结果反映到相关的地方,你会做很多努力。比如库存的及时同步。
如果在特殊时期,能够临时降低对时效性的要求(3秒内生效变成30秒生效),也是一个有不错收益的方案。
比如原先在商品页会显示当前还剩多少个库存,现在可以调整成固定显示「有货」。
以及将一些原本就是异步进行的操作,处理效率放缓,甚至暂缓一段时间。如,送积分、送券等等。
讲了这么多,降级具体实施起来要怎么做呢?
二、「降级」怎么做
主要分为两个环节:定级定序和降级实现。
定级定序
就像前面的例子中提到的一样,首先我们得先确定每个功能的「重要程度」,它决定了在什么情况下可以抛弃它以保证剩下的功能可用。
类似于给日志定义级别一样,比如我们可以定义1~5五个级别,1的级别最高,要拼死保护。5的级别最低最先可以被降级掉。
一旦当系统压力过大的时候,先把级别5的功能降级掉。如果还不够再降级别4、级别3,以此类推。
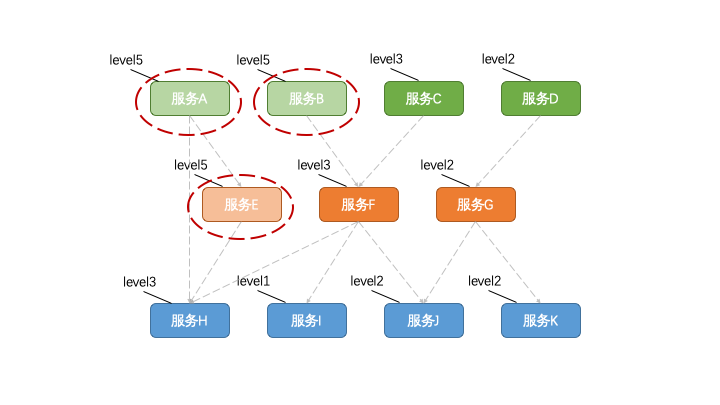
但实际上光这样定级还不够,比如被定义为4级的有100个功能,需要降级的时候是一起降级吗?很明显粒度太粗了。
如果「定级」好比是横着切蛋糕的话,「定序」就是再来竖着切。

我们也可以来定义一些数字,比如序号1~9,序号9最先被降级。
然后,你可以以每个程序所支撑的上游程序/功能数量作为一个参考标准。比如,同样是级别5的程序,一个支撑了上游5个功能,一个支撑了10个功能,很显然前者的序号应该更大,更先被降级。
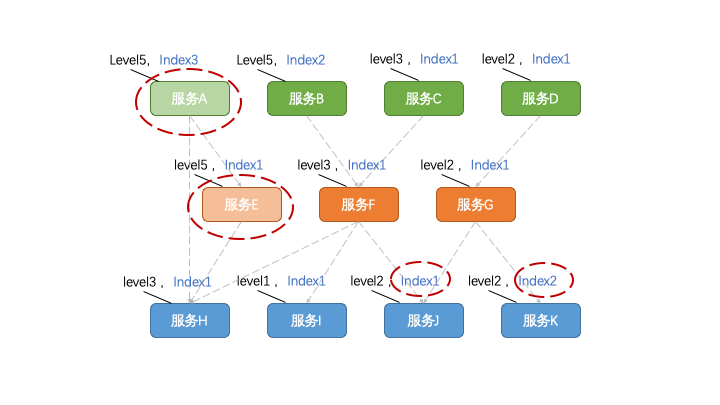
当然,根据所支撑的功能数量只是一个「业务无关性」的通用办法。如果想精益求精,还需要对每个功能做「作用」上的分析,毕竟不同功能之间的相对重要性还是有所差异的。(这里可以扩展了解一下Analytic Hierarchy Process,层次分析法,简称AHP)
对了,定级定序的时候有一点是需要格外注意的:某个程序所依赖的下游程序的级别不能低于该程序的级别。
为什么呢?因为一旦所依赖的程序被降级了,自然会导致其所支撑的所有上游程序不可用。所以,其上游程序的等级再高也是没有意义的。
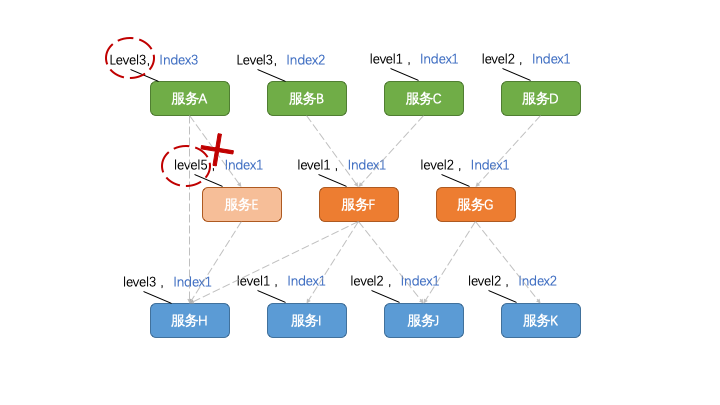
至此,完成了“排兵布阵”,接下来就是“实施运作”了。
降级实现
首先要制定触发机制。这同熔断、限流一样,什么时候该触发「降级」这个动作也需要依赖提前制定的一些策略。这部分内容和前面两篇(熔断、限流)类似,无非是接口的超时率、错误率,或者系统的资源耗用率等,这里就不重复展开了。
当程序发现满足了降级条件进入「降级模式」后,程序该如何处理请求呢?
全局变量 int _runLevel = 3; //运行系统级别,默认值5全部变量 int _runIndex = 7; //运行系统序号,默认值9//以下是一个level=4、index=8的功能示例。if(myLevel \u0026gt; _runLevel and myIndex \u0026gt; _runIndex){ // 进入降级模式。}else{ // do something...} 题外话:通过Aop+注解(特性)的方式来做上面的if判断是一个爽的事情。
虽然处理请求的方式有很多,但特别强调的是,要实现的降级策略要尽可能的简单。因为「边际效应」的存在,为了应对突发状况把事情反而搞复杂了就得不偿失了。
那么在实现部分,如果是前端。我们比较常见的是:
- 在返回的http报文中通过Cache-Control的设置,让后续的请求直接走浏览器缓存。
- 页面中原本需要异步加载的数据,直接不加载。
- 禁用部分操作按钮,甚至直接告知“临时关闭”。
- 动态页面的url通过反响代理切换到静态页面返回。
这里面除了禁用按钮外,大部分事情都可以在接入层,如nginx中处理掉,这样可以避免对业务项目的代码侵入。
如果是后端程序的话,针对「读」类型的操作,可以将“// 进入降级模式”部分代码写成下面的样子:
- 如果是无返回值方法。默认return或者throw一个异常。
- 如果是有返回值方法。默认返回本地mock的数据或者throw一个异常。
后端部分如果有使用一些中间件的话,直接在中间件(rpc、mq代理等)中处理掉是极好的(一般会内置一个fallback接口待实现),如此也可以避免对业务代码的侵入。
最后我们来聊聊后端程序的「写」问题。
缓存是大型系统中的常客,随着系统规模越大,为了在性能和成本上寻求更优,不可避免的会增加复杂度引入多级缓存。如此就会变成:本地缓存 --\u0026gt; 分布式缓存 --\u0026gt; DB/源服务,这样的一个层层递进的关系。
平时的代码可能是这样的:
if(write数据库(data) == true){ if(write分布式缓存(data) == true){ write本地缓存(data); return success; } else{ rollback数据库(data); return fail; }}else{ return fail;} 在高负载时期,我们可以降低对一致性的要求。将耗时的「数据落盘」操作降级为「异步」进行。
if(write分布式缓存(data) == true){ write本地缓存(data); pushMessage(data); //发出的消息可以通过集中式的MQ、也可以直接写本地磁盘。 return success;}else{ return fail;} 甚至,如果可以的话能做的更彻底,同步到分布式缓存也异步进行。
write本地缓存(data); pushMessage(data); //发出的消息可以通过集中式的MQ、也可以直接写本地磁盘。return success;
数据库是系统的最后一座堡垒,非非非常极端的情况下,我们可以把一些「写数据」操作在「数据库访问框架」中给禁用了,让给所有资源都给到「读数据」。使得系统从表象上来看至少还是“活着站在那”的,虽然很多功能操作一下就是返回失败(这不也是实在没办法了嘛,面子得要啊,死撑~)。
三、总结
至此我们聊了做降级的思路以及最常见的一些实现方式,但是真正要把降级最好是一个任重而道远的过程。
从方案的角度来说,如果降级的过程需对每个功能/程序逐一进行,那么理论上10个功能点就可以产生P(10,10)= 3628800种方案。
再从现实的角度来说,流量又是不可预测的。某些功能可能这次需要作为level2来看待,下次其实作为level3就够了。
所以这是一个需要长期不断打磨和调优的过程。
最后,希望近期的「高可用三剑客」可以作为你了解「高可用」的起点,可以先收藏防身(当然再分享一下也是极好的:)),欢迎后续一起交流探讨~
Question:
你曾经是否有遇到过什么场景,当时是通过马上改代码来「降级」呢?欢迎来吐槽~关于作者:
张帆(Zachary),7年电商行业经验,5年开发团队管理经验,4年互联网架构经验,目前任职于某垂直电商技术总监。专注大型系统架构、分布式系统。坚持用心打磨每一篇原创。本文首发于公众号:跨界架构师(ID:Zachary_ZF)。转载地址:http://xjzox.baihongyu.com/